
spotmarket Prototyping
Posted: 2016-01-17 Filed under: python, spotmarket | Tags: amd, asus, mysql, postgresql, tweetfleet Leave a commentThe past few months have been a series of shifting goals and commitments for me, both personally and professionally. I’ve spent more time outside running trails in the Marin Headlands and I changed jobs, landing a engineering role at a trading firm.
The winter months in San Francisco mean rain, and as such, I have been spending a lot of time reading Python tutorials, collaborating with James and Greg at element43, and working on a list of design requirements for the spotmarket trading platform.
The biggest addition to the project has been the buildout of a proper homelab server running ESXi. I’ve wanted to build out a homelab since I’m a network engineer and often tinker, but I’ve never really had a driver for the project. For the odd virtual machine or instance of a virtual switch/router that I’ve needed, I’ve leveraged an install of Oracle VirtualBox on my desktop. Now that I want to run development, production, and other testing machines, I built out a server.
Server ‘esx-01’, Uninspired Name
I ended up running ESXi 5.5 because I struggled to get my ‘unsupported’ NIC to work in 6.0. I followed a few guides to load drivers into the installation ISO, but was unable to get the setup procedure to complete properly for 6.0. My needs are basic on the VMware end so I’m sticking with 5.5 as I was able to get that to install with Realtek 8168 onboard NIC.
Details for the build:
- ASUS M5A99FX PRO R2.0 Motherboard
- AMD FX-8320 Vishera 8-Core 3.5 GHz CPU
- SanDisk Ultra II 2.5″ 480GB SSD
- G.SKILL Ripjaws X Series 16GB (2 x 8GB)



Python Learning
I was in a computer engineering program for two years in college before switching over and finishing in a telecommunications program. During that time I was exposed to assembly, C, and C++. I spent many late nights struggling with those languages, so I was apprehensive to dive back into programming.
I picked Python as the main language for this project and so far it has been outstanding. I’m getting more comfortable with the Python datatypes, iterators, and reliance on indentation. For data manipulation I’m using pandas, which for anyone that loves rows and columned data, it is second nature.

Another item that has taken a lot of brain time has been the switch from MySQL to PostgreSQL. I’ve had to learn about the use of schemas, differences in data types, how to enable TCP access, and migrate my administration/query generator tool over to pgAdmin.
The Chats
If you have any comments or want to chat with me, find me on the new #k192space channel at tweetfleet.slack.com. Upcoming posts will delve into coding and talk about the reporting that I’ve started to build.
Challenges of Archiving Industry Index Values
Posted: 2014-08-20 Filed under: eveonline | Tags: api, arm, crest, mysql, raspberry pi 6 CommentsIf you have any interest in 3rd party development or databases, this post will be a entertaining as I share my current lackluster architecture for saving some of the new Eve API data.
I have a Raspberry Pi running MySQL that I use as a basic storage location for various databases. One of them is a new database that contains index values from the CREST API endpoint with a timestamp so I can start to develop a archive of the values.
The current solution I have for importing the new Index data isn’t very elegant. I’m using Lockefox’s Crius Toolset sheet to grab a CSV every day, adding two columns for a primary key and a timestamp, and importing into my table to get a table that looks like this:
“transactionID” “transactionDateTime” “solarSystemName” “solarSystemID” “manufacturing”
“103724” “2014-08-19 13:28:00” “Jouvulen” “30011392” “0.0339317910000”
“103725” “2014-08-19 13:28:00” “Urhinichi” “30040141” “0.0236668590000”
“103726” “2014-08-19 13:28:00” “Akiainavas” “30011407” “0.0285709850000”
“103727” “2014-08-19 13:28:00” “Seitam” “30041672” “0.0162879230000”
“103728” “2014-08-19 13:28:00” “BK4-YC” “30003757” “0.0143238350000”
It’s growing and starting to show how under-powered the Raspberry Pi is for data processing. Most of my issue stems from a lack of salable design on my part. I have no table indexes and am joining with the bulky mapDenormalize table.
I have a love-hate relationship with the mapDenormalize table. If you have ever worked with this table, you know that it is a beast: 502,558 rows, 15 columns with five of them being DOUBLE values coming in at 214MB. Normally not a problem for server with a lot of CPU cycles and RAM, but the 700MHz ARM processor on the Raspberry Pi has a hard time with multiple JOIN operations and GROUP BYs.
Here’s a query I was running against my dataset that ran for 15.5 minutes (!).
SELECT systemCosts.solarSystemName, systemCosts.transactionDateTime ,systemCosts.manufacturing, mapRegions.regionName, mapDenormalize.security
FROM systemCosts
JOIN mapDenormalize
ON (systemCosts.solarSystemID = mapDenormalize.solarSystemID)
JOIN mapRegions
ON (mapDenormalize.regionID = mapRegions.regionID)
GROUP BY transactionDateTime,solarSystemName
So two full table JOIN and two GROUP operations and a table with no indexes, uf. I sent a screenshot off to James, my development partner.

My first solution was to remove extraneous data from the mapDenomalize table. After removing the groupID, constellationID, orbitID, x, y, z, radius, celestialIndex, and orbitIndex I trimmed the table down even further by deleting all entries that were not star systems. What was left was 7,929 rows coming in at around 1MB.
I’m glad to report that my terrible query is now running in 20 seconds. This was a small step to getting my growing index dataset to a usable state while I write something more permanent.
Eve Development Environment
Posted: 2014-03-14 Filed under: eveonline, market | Tags: heidisql, mysql, ubuntu 5 CommentsOverview
The following guide covers details on how to setup your own Eve Development Environment on your local machine. Using these directions you can create a master Virual Machine template, import the Eve Static Data set into a MySQL database, and query it with a database management program.
I plan on having further guides on running other pieces of software. I want to write guides for Lockefox’s Eve-Prosper tools and the once active Wallet Manager program that I have blogged about; once I learn how to create a public repository on GitHub, I will have a guide on how to run it from a template VM as outlined in this guide.
Virtual Box Setup
Rather than install server services on your local machine, we’re going to isolate them in a Virtual Machine that can be backed up and cloned into unique instances for our needs.
- Download and install Virtual Box here.
- Download Ubuntu Server ISO image here. Since we won’t be interfacing over the GUI, we can lessen the resource consumption of the VM by going with the Server edition.
- Create a new Virtual machine named evedev1

- Select 512 or 1,024 MB of RAM depending on how much you have on your desktop and how quickly you want your Development machine to run. The more RAM the better, but with the Eve static data set coming it at 525 MB, you will reach a diminishing return after the majority of the data gets into RAM. You can always adjust this setting by powering off the VM if you find performance to be problematic.
- Create a virtual hard drive now.
- I’m partial to the VMDK format given my VMware background.
- Select Dynamically allocated as not to claim empty space on your machine.
- Specify 8 GB of storage to start or more depending on how much free space you have available. The base server install will take around 1.2 GB.
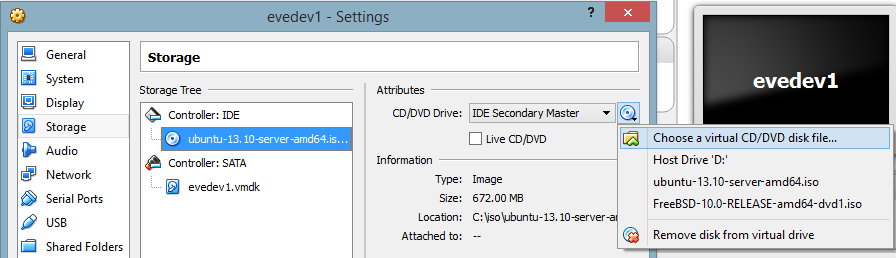
- Go to Settings on the evedev1 machine and Chose a virtual CD/DVD disk file. Select the Ubuntu Server ISO that you previously downloaded.

- Start the VM.
Ubuntu Server OS Setup
I prefer Ubuntu but you may want to use any number of Linux distributions.
- If your ISO is mounted correctly, you will be presented with a Ubuntu boot screen.

- Select Install Ubuntu Server.
- Select your language, location, and keyboard mappings.
- Name the machine evedev1
- Create a evedev user.
- Create a password for the evedev user.
- Under partition disks select Guided – use entire disk. Since this is a Development VM, we will most likely not be using LVM.
- Select the partition and on the next screen write the changes.
- Allow apt to run to update packages.
- Select Install security updates automatically.
- Only select the OpenSSH server for now as we will be installing the database separately.
- Install the GRUB boot loader.
- After the installer finishes, reboot the VM.
- If everything is setup correctly, you should see a login prompt.
Creating a Template VM Image
This process gets us to a point where we have a base OS with patches installed. If we make any steps we can revert back to this image and also use this to spin off future copies of VM instances.
- Login as evedev with the password set during the install.
- Update local package database index with sudo apt-get update
- Update local packages with sudo apt-get upgrade. This process will take a while depending on the speed of your machine.
- Shut down the VM with sudo shutdown -h now
- If you want to make a backup of this file, do it now. We will consider this our Template VM image for making future clones.
Database Setup on a New Clone
- Create a Clone of evedev1 by right-clicking on the evedev1 machine and selecting Clone
- Name this clone evedev1-mysql and select Reinitialize the MAC address of all network cards.
- Select Full Clone.
- Power on the evedev1-mysql instance.
- Log in and check the IP address of the machine by using ifconfig.
- SSH into the IP address of your VM using PuTTY. I find that using PuTTY is more efficient than the Virtual Box interface since we will be pasting a long URL and will enable us to remotely access the database later.
- Install MySQL with sudo apt-get install mysql-server
- Set the mysql root user password.
- Find the latest MySQL conversion of the Eve Static Data at https://www.fuzzwork.co.uk/dump/.
- Copy the link of the latest conversion to your clipboard and download it with wget https://www.fuzzwork.co.uk/dump/mysql56-example.tbz2
- Uncompress the file with bunzip2 mysql56-example
- Un-tar the file with tar -xvf mysql56-example
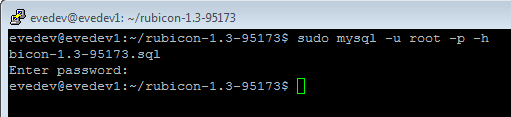
- Change directory with cd rubicon-1.3-95173
- Enter the MySQL Monitor with sudo mysql -u root -p
- Create a new empty database with create database rubicon95173;
- Exit with exit;
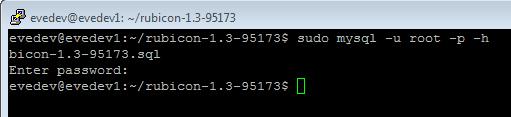
- Import the extracted .sql with sudo mysql -u root -p -h localhost rubicon95173 < mysql56-rubicon-1.3-95173.sql
- Wait for the import process to complete. The import took around 6 minutes on my laptop.
Remote Database Management
I prefer HeidiSQL to access the database, store queries, and edit table structures.
- Download and install HeidiSQL.
- Create a new Session and fill in the details for your VM. The details on the Settings tab will be the MySQL root user credentials for Hostname 127.0.0.1.
- Under the SSH tunnel tab, specify the location of your PuTTY executable. The SSH host + port will be the IP address of your VM such as 192.168.0.20 on port 22. The credentials on this tab will be for the evedev account.
- If successful, you should see our imported database and tables.


Running Queries
I wrote a guide on the basics of the Eve Static Dataset and some sample queries here.
Working With API Wallet Data
Posted: 2013-04-15 Filed under: eveonline, industry, market | Tags: marketgroupid, mysql, sql, typeID 3 CommentsOverview
The audience of this post is a person that has a database table that is populated from the /char/WalletTransactions.xml.aspx API and wishes to use queries to produce meaningful, intelligent results that can be used to help focus trading operations.
Even with limited database query knowledge, we can derive meaningful Business Intelligence out of our dataset. Basic MySQL/SQL knowledge is recommended as values or parts of an example query may need to be modified to suit your environment or table structure.
I won’t cover the design on how to get API data into your database table here as I want to save that topic for its own post. If you need an answer to populating your database from the API, search the Eve Forums as there are a many projects that can help.
Prerequisite
Wallets from multiple characters are stored into a database table.
phpMyAdmin or SQL Server Management Studio for running and manipulating queries.
Business Intelligence from Numbers
Knowing that a Drake sold for 1.1 M profit one time doesn’t tell you much in the larger scheme of your business as we need to extract more intelligence out of our numbers. Getting further metrics out of the wallet data can help focus your operation and deliver better results.
Consider these starter questions: How fast have Drakes been selling (item velocity)? Are the the monthly profit from Drakes worth your time or should you be working with another item? Is working with Tech1 Battlecruisers proving profitable?
These are examples of the types of questions that you can answer with a few database queries and some spreadsheet analysis. The more robust developer will build these queries into a reporting application, but for the purpose of this post, I will stick to running a query and working with the output.
Table Structure
I have added a few unique columns to my table to help me filter my data. Here is my ‘wallet’ table structure for reference.
— Table structure for table `wallet`
CREATE TABLE IF NOT EXISTS `wallet` (
`transactionDateTime` datetime NOT NULL,
`transactionID` bigint(20) unsigned NOT NULL,
`quantity` bigint(20) unsigned NOT NULL,
`typeName` varchar(255) CHARACTER SET latin1 NOT NULL,
`typeID` int(11) NOT NULL,
`price` double unsigned NOT NULL,
`clientID` bigint(20) unsigned NOT NULL,
`clientName` varchar(255) CHARACTER SET latin1 NOT NULL,
`characterID` int(11) NOT NULL,
`stationID` bigint(20) unsigned NOT NULL,
`stationName` varchar(255) CHARACTER SET latin1 NOT NULL,
`transactionType` varchar(4) CHARACTER SET latin1 NOT NULL,
`personal` tinyint(1) NOT NULL DEFAULT ‘0’,
`profit` double NOT NULL DEFAULT ‘0’,
PRIMARY KEY (`transactionID`),
KEY `characterID` (`characterID`),
KEY `transactionDateTime` (`transactionDateTime`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
characterID, personal, and profit are unique columns that I use to help track items for reporting purposes.
- characterID – I have multiple character wallets writting to this table so I have a ID for each one stored in a characters table.
- personal – this is a 0/1 flag that I use to note if an item in the wallet is for personal use. Examples are fuel for jumping capitals or ammo for PVP adventures.
- profit – calculated profit of the item when sold minus fees.
Examples
— Total Profit per Item
SELECT typeName, typeID, SUM(profit)
FROM wallet
AND personal = 0
GROUP BY typeID
ORDER BY SUM(profit) DESC— Price and Profit sums per Month in 2012
SELECT MONTH(transactionDateTime) AS calMonth, SUM(price) AS price, SUM(profit) AS profit
FROM wallet
WHERE transactionDateTime LIKE ‘2012-%’
AND personal = 0
GROUP BY MONTH(transactionDateTime)— Total Profit and Sales per day
SELECT DATE(transactionDateTime) as date1, SUM(profit) as totalProfit, SUM(price) as totalPrice
FROM wallet
AND personal = 0
GROUP BY date1
ORDER BY date1— Average Margin and Total Quantity per Meta Group over the past 365 days
SELECT invMetaTypes.metaGroupID, invMetaGroups.metaGroupName, AVG((profit / (price * quantity))) * 100 as averageMargin, SUM(quantity) AS quantity
FROM wallet
JOIN invMetaTypes ON (wallet.typeID = invMetaTypes.typeID)
JOIN invMetaGroups ON (invMetaTypes.metaGroupID = invMetaGroups.metaGroupID)
WHERE transactionDateTime > DATE_SUB(CURDATE(),INTERVAL 360 DAY)
AND transactionType = “sell”
GROUP BY invMetaTypes.metaGroupID
ORDER BY metaGroupID–Market Groups
SELECT wallet.typeID, wallet.typeName, SUM(profit) as totalProfit, SUM(quantity), SUM(price), b.marketGroupID, a.marketGroupName, b.marketGroupName as parentName1, c.marketGroupName as parentName2, d.marketGroupName as parentName3
FROM wallet
JOIN (invTypes, invMarketGroups as a, invMarketGroups as b, invMarketGroups as c, invMarketGroups as d)
ON (wallet.typeID = invTypes.typeID
AND invTypes.marketGroupID = a.marketGroupID
AND a.parentGroupID = b.marketGroupID
AND b.parentGroupID = c.marketGroupID
AND c.parentGroupID = d.marketGroupID)
AND personal = 0
AND d.marketGroupID = 11
GROUP BY wallet.typeID
ORDER BY totalProfit DESC
Flex Your Database Muscle
These examples should serve as a branching off point as you will want to tailor them to your operation. You may want to replace SUM with AVG or COUNT, modify the date range to take a look at a specific trading period, or hopefully roll these types of queries into a reporting engine to really drive your business intelligence.
Data Warehousing using EVE Market Data Relay (EMDR)
Posted: 2013-02-20 Filed under: eveonline, industry, market | Tags: api, cron, csv, emdr, eve-central, mysql 3 CommentsOverview
Knowing the price and volume of items moving in the Eve market at a specific point in time is a very powerful piece of information that can help further your space empire.
Historically eve-central was the repository of market data but with new advances in cache scraping, data transport methods, and large archival storage methods have brought us exciting new capabilities.
tl;dr EMDR
What the heck is EMDR and why should I care?
Original implementations of market aggregation sites had a user click the Market Export button in the Eve client to produce text files in their local Documents\EVE\logs\Marketlogs folder and then use an application to transfer the exported files to a database. This method was tedious, lacked region and item coverage, and was prone to people editing the data before it was sent off.
A renascence was generated when developers began to explore the cache in the Eve client. The client cache is a location that serves as temporary storage for information that you are working with in the client; it is volatile and changes all the time rather than holding static art, formulas, or universe data as seen in the client .stuff files.
EMDR is a service that takes market orders from the cache of your local client and sends that immediately upon viewing it in the client to a relay service that people can subscribe to. If you click on an item in the market window, that piece of data is immediately sent off to many people that can receive it. The transfer is quick, the data is not tampered with, and it can easily be relayed to many interested parties. This is pure data, a statisticians dream!
Working with Eve-Central
What follows are notes from my partner, Raath, who has been withing with the EMDR method to improve our industrial operation.
When I first began adding price dependencies to the DRK Industry Tracker, it was back in the day before we had the EMDR. Eve-central was the bespoke out of game price lookup service and with the aid of their API I pulled prices from there.
At the time I don’t think it had the option to do a full pull of prices on every item in game so I devised a system where the tracker would cache prices locally and update them when they were older than an hour on a need to know mechanic so only the relevant data was requested.
I did this so that I didn’t swamp eve-central with hundreds of requests every hour for information that 95% of which would never be used. It was a system that worked well except for the occasional lag caused by the prices updating. As I said before, it only updated when prices were older than an hour as the users requested them. But when I started to think of releasing the tracker publicly, I needed something a little more reliable.
Transition to EMDR
At this point in time the EMDR was a fully developed solution so I started to look into how I could begin using this as my price basis and integrating data into our industrial workflow. Not really knowing the volume of information that would soon be assaulting our little virtual machine, I make a few mistakes.
Flood of Data
The term for the EMDR feed that people have adopted is the “fire hose” as it is literally a flood of overwhelming data being constantly sent at you with no regard for your ability to process it. As clients all across the world are clicking around the market window, updates are being sent to you in near real-time. The function name of “engage_fire_hose” only seemed natural.

Statistics
Our Industry site currently consumes 8 gig of data, serves 6-700 MB and calls around 150,000 API requests per day with the vast majority of our incoming data coming from the EMDR updates. In January we received 179 GB and sent 17 GB for an average of 5.8 GB/day of incoming data.

Processing Challenges
With the large amount of incoming price data, we needed to be able to efficiently process and store it while keeping the server responsive.
The first method I devised was a system where I stored transactionIDs in a hash table. This design soon showed its weakness as we hit a memory limit when the hash table started to fill up with millions of transactionIDs.
Additionally my attempts to keep load on MySQL server down were also in vain as the information was coming in so quickly that my consumer was having trouble keeping up. We soon had problems with locked rows and inserts failing so I had to completely revise my entire approach.
What resulted was a consumer process that guzzles around 8 GB of data per day and spits all the information to CSV files. There is no logical processing done in the consumer now, it just munches and spits data to file. Another cron job that runs every minute scans the temp file directory for CSVs, parses them all into one single large CSV, and then performs a LOAD DATA IN FILE into MySQL, a method which I’ve found is not only lightening fast but also keeps the load down.
Not all of the data is useful as the majority of it is duplicates. When the server has free time, we run a cleanup process in the form of flag checking remove expired records so that the data we display is as up to date.

Future Plans
All this work for clean price data. We have plans to further expand some of the market data functionality in projects to start using the cached market history to show the historical price or items and build costs compared to live data.

{kind=link}