
spotmarket – 0.6
Posted: 2016-06-07 Filed under: python, spotmarket 1 CommentProject Update
Basically…


via @ThePracticalDev
Work on the spotmarket project has staled as I have a major work deliverable coming up at the end of the month. I’ve figured out some things, have found pain points that I need to optimize, and the wonderful nature of feature creep keeps adding more and more to the growing list of items that I need to work on so I never feel like I’ve made any progress.
Data Errors
After the XML API moved to the new London datacenter, I started to notice a small uptick in ratting and kill rates. I didn’t bother to investigate and kept on happily coding. As I was reworking the schema and moving data to different tables, I performed a check against the dataset and discovered duplicate entries that were a second off occurring 3-4x a day.

I’m using the cachedUntil value of the API as my timestamp with timestamp and solarSystemID as my primary key. I have a process that fetches the data multiple times an hour and performs an import. I’ve been told by multiple people not to not use cachedUntil as the timestamp, but this is what I’ve coded the first time around.
I reached out to CCP FoxFour and it seems that I shouldn’t be seeing timestamps off by 1 second.
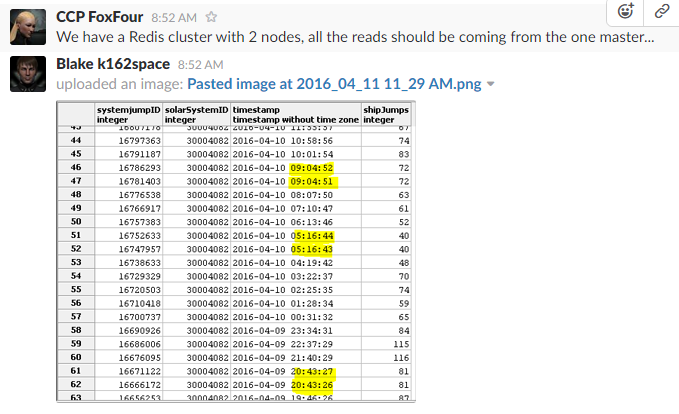
I have a temporary fix for this, which is manually running a python process to iterate over all solarSystemIDs and correct duplicate data via a JOIN query. The real fix will mean reworking the consumer script.
Parallel Tasks
The biggest advancement in my project came this month when I learned how to use Python concurrent.futures. Recording market prices at 0.8 records/second isn’t exactly the best way to scan 8,300 items across multiple regions.
Python concurrent.futures to lets you asynchronously execute callables. This means that I can create a worker pool and submit jobs to it. As each worker finishes, it will get a new job.
Here are 8 requests in my market scanner:
[Domain][typeID:19][Spodumain]
[Domain][typeID:35][Pyerite]
[Domain][typeID:34][Tritanium]
[Domain][typeID:21][Hedbergite]
[Domain][typeID:22][Arkonor]
[Domain][typeID:18][Plagioclase]
[Domain][typeID:20][Kernite]
[Domain][typeID:36][Mexallon]
What’s so interesting about this? Check out the order — the jobs were submitted in order (typeID 19, 20, etc.) and returned out of order because they finished at different times.
I scaled the import process up to 16 workers (8 cores x 2) and was able to scan 8,300 prices in about 30 minutes.

I have some work to do where I want to change the insert portion to only insert new data. Right now it is throwing the entire response into the database and relying on key constraints to dedupe.
Characters
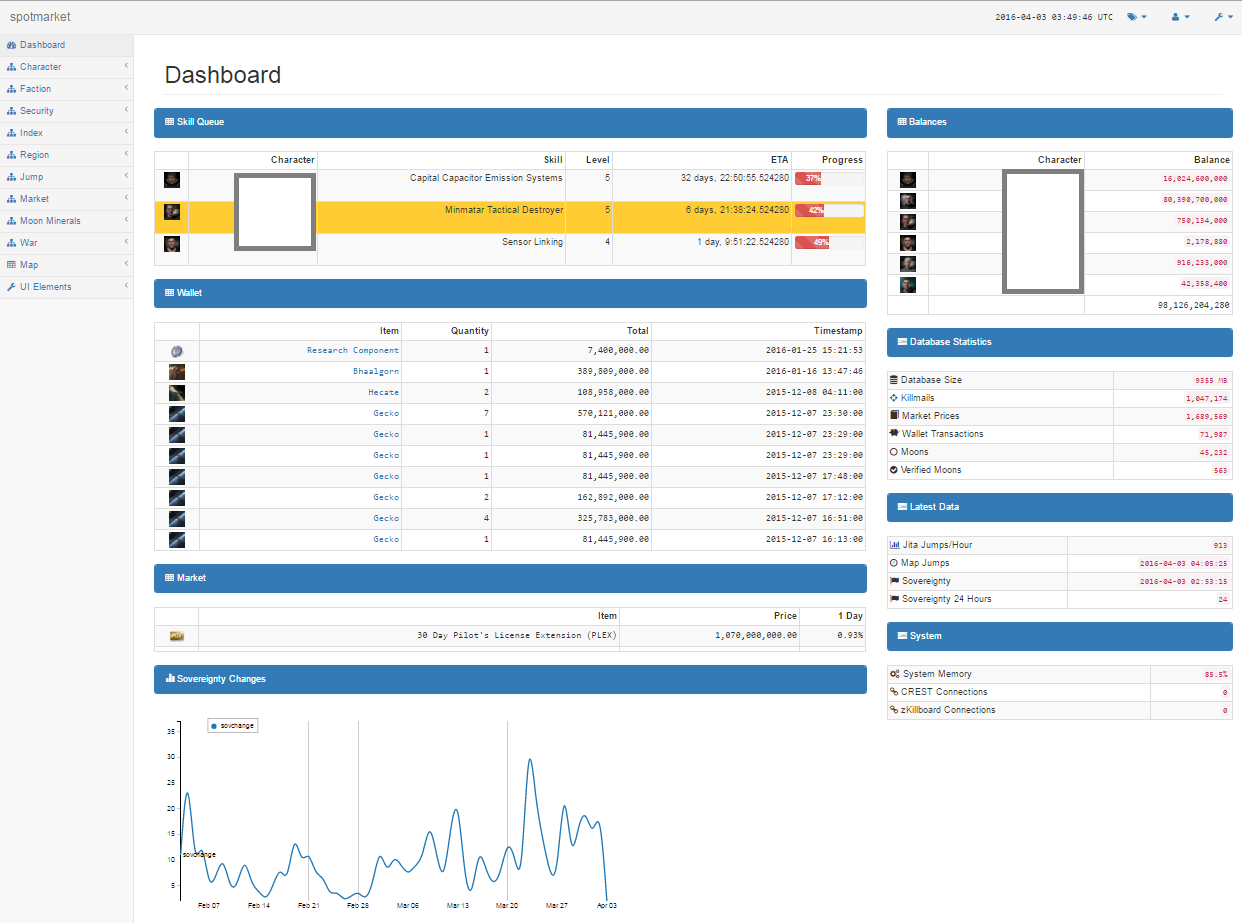
The previous trading platform was good at showing transactions, balances, and item trends so I started to replicate a lot of the features. For a first pass, I wanted to start to integrate Character information so I added API processes for Wallet, Orders, and Blueprints. I’ll finish up with Journal and Assets in the next pass.
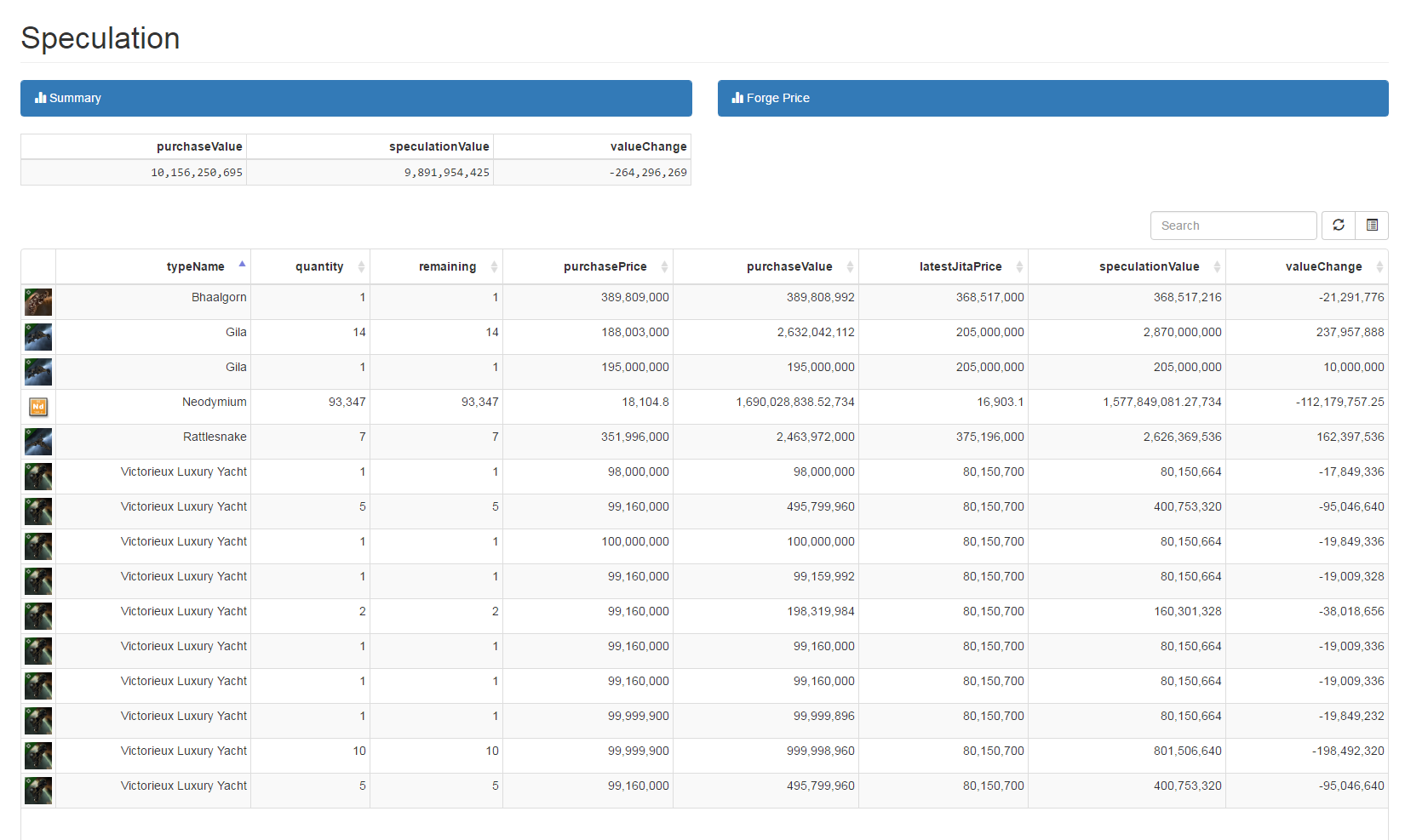
Speculation
I’ve started to put my foot into the speculation market and built up a page to track my investments. Getting items into the table isn’t elegant, you have to throw a transactionID at an API endpoint so it records it from the wallet table into the speculation table.
I don’t have enough jQuery knowledge to create buttons to post to a API endpoint yet. Adding the ability to write back to the database will bring a lot of interaction to the project so it’s high on the list.

I’m following your work since… a long time. And you seem to always looking for performances. I’ve read this article today, maybe it could be great for your project: http://magic.io/blog/asyncpg-1m-rows-from-postgres-to-python/
It’s an alternative to psycopg2 and seems great.